이전 내용 :
2024.01.29 - [자격증/SQLP] - [SQLP 요약] 제 5장 인덱스와 조인 (1절 인덱스 구조 및 종류 이해) - (1/4)
[SQLP 요약] 제 5장 인덱스와 조인 (1절 인덱스 구조 및 종류 이해) - (1/4)
더보기 SQLP 시험 영역 중 "과목 3. SQL 고급 활용 및 튜닝"에 대한 강의(개인적으로 수강 중인 교육)를 요약해서 업로드하려 한다. (사실 강의에서 매주 숙제가 그 주 수업 요약이다) 나도 나중에 시
holog.tistory.com
🏳️🌈 이번 주 목차
제 5장. 인덱스와 조인
└ 1절. 인덱스 구조 및 종류의 이해
├ 1. 인덱스 구조
├ 2. 인덱스 기본원리
├ 3. 다양한 인덱스 스캔방식
├ 4. Oracle DBMS 구조
├ 5. 테이블 랜덤 액세스 부하
├ 6. 테이블 Random 액세스 최소화 튜닝
├ 7. IOT와 클러스터
├ 8. 인덱스 스캔 효율
├ 9. 인덱스 종류
└ 10. 인덱스 설계
└ 2절. 조인의 원리와 활용
├ 1. Nested Loop 조인
├ 2. Sort-merge 조인
├ 3. Hash 조인
└ 4. 조인 순서의 중요성
8. 인덱스 스캔 효율
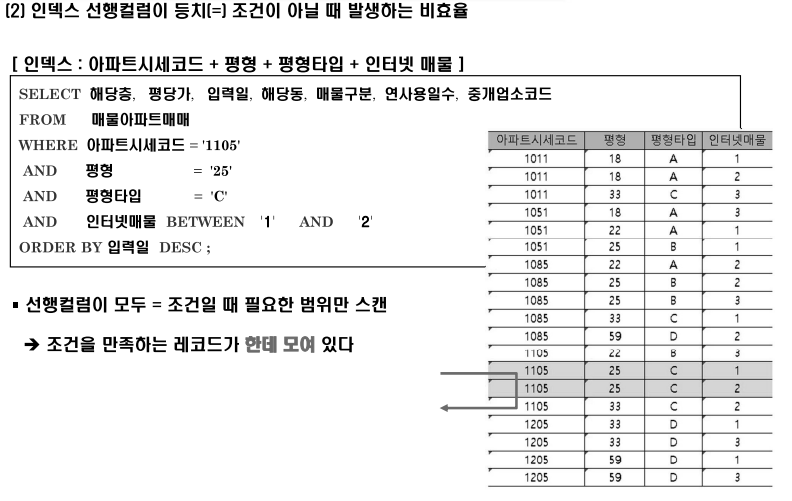
➡️ 인덱스 선행 컬럼이 등치(equal = ) 이 아닐 때 발생하는 비효율 !
이게 무슨말이냐면, 인덱스 선행컬럼이 범위조건이고 후행 컬럼이 equal 이라면.. 일단 범위로 다 읽고 그 중에 equal로 선택해야 하는 상황이 생긴다. 고로 굳이 안읽어도 되는 범위를 읽고나서 filtering 하는 것을 말한다.
1. Sequential 액세스 효율은 선택도에 따라 결정된다.
2. 인덱스 컬럼이 조건절에서 모두 = 일때 당연히 가장 액세스 효율이 좋다
3. 리프 블록을 스캔하면서 읽은 레코드 전체가 필터링 되지 않고 그대로 테이블 액세스 했다? ▶️ 비효율이 전혀 없었다
4. 인덱스 컬럼 중에 조건절에서 빠지더라도 그게 인덱스 뒤 컬럼이라면.. 어차피 다 읽어야 하므로 비효율이 없다!
위 내용을 그림으로 보면 아래와 같다.

그럼 직전의 비효율적인 구조를 쿼리를 변형하여 아래와 같이 인덱스 비효율을 없앨 수 있다.
⭕ Between 조건을 IN-List로 변경하였을 때 인덱스 스캔 효율!

위 쿼리는 내부적으로 아래 쿼리와 동일하게 작용된다.

위처럼 Union all로 풀리는 경우와 동일하다 보니 아래와 같이 주의 사항이 있다.
1. IN-List 개수가 많지 않아야 한다.
이유는 2번이다.
2. 수직적 탐색이 IN-List 개수만큼 발생한다.
3. 수평적 스캔의 비효율보다 수직적 탐색에 대한 비효율이 더 클수 있다.(인덱스 높이가 높을 때 비효율이 커진다)
저번에 과제에서 낚였던 부분이 이거였다. 인덱스 구성을 IN 절을 사용하는 조건을 앞에 놓았는데.. 오히려 Range 스캔의 비효율보다 IN 절에 의한 수직적 탐색이 더 비용이 높았던 것이다. 그래서 반드시 두개를 비교해는게 좋을 듯 하다.

경우에 따라서 위처럼 Between 조건이 좋은 경우가 있으니 꼭 확인하자.
✅ 그리고 보통 실제업무에서도 가장 아래처럼 나오는 경우가 많고.. 시험도 보통 저렇게 많이 나온다니 꼭 확인하자
그리고 IN-List와 INDEX_SS을 비교할 때.. 예를들어
-- 인덱스 : 판매월 + 판매구분
WHERE 판매구분 = 'A' -- 분포 안좋음
-- 1.
판매월 BETWEEN '202301' AND '202312'
-- 2.
판매월 IN ('202301', '202302', '202303', .... , '202312')
-- 3.
판매월 BETWEEN '202301' AND '202312' /*+ INDEX_SS() */라면.. 3번의 INDEX_SS의 경우가 IN-List보다 좋을 때도 있다. 왜냐하면..
INDEX_SS의 경우 Root 블록까지 가지 않고 Branch 까지만 가고 점프하기 때문에 CR로 읽히지 않기 때문이다.
위 내용이 아래 사진이다.


✅하지만 답안 작성할 땐 IN-List가 가장 명확하니 IN-List로 쓰자
🔶 범위검색 조건을 남용할 때 발생하는 비효율
인덱스(상품코드, 주문일자, 주문유형) 일 때
-- 1번.
WHERE 상품코드 = 'A'
AND 주문일자 = :DT -- '20230101'
AND 주문유형 = '1'
-- 2번.
WHERE 상품코드 = 'A'
AND 주문유형 = '1'1번의 경우 비효율이 전혀 없지만 2번처럼 주문일자 컬럼이 빠지면 비효율이 발생한다.
또한 개발자의 편의를 위해 주문일자를 아래처럼 LIKE로 변경한다면 이 또한 비효율이 발생할 수 밖에 없다.
-- 3번.
WHERE 상품코드 = 'A'
AND 주문일자 LIKE :DT || '%' -- '20230101'
AND 주문유형 = '1'보통 파라미터가 있거나 없거나 하나의 SQL로 사용하려다 보면 저런식으로 할 때가 있다.
그럴 경우 아래와 같은 방식으로 SQL을 변경해주자.
-- 4번.
WHERE :DT IS NOT NULL
AND 상품코드 = 'A'
AND 주문일자 = :DT -- '20230101'
AND 주문유형 = '1'
UNION ALL
~~
WHERE :DT IS NULL
AND 상품코드 = 'A'
AND 주문유형 = '1'
;
-- 5번.
WHERE 상품코드 = 'A'
AND 주문일자 = NVL(:DT, 주문일자) -- '20230101' -- DECODE도 UNION ALL로 풀 수 있다.
-- CASE WHEN을 사용하면 UNION ALL로 안풀리니 조심!!
AND 주문유형 = '1'✅ 5번의 경우는 주문일자 컬럼이 NOT NULL 이어야만 사용 가능하다.
✅ 5번 쿼리의 핵심은 주문일자 = 주문일자 조건이 모든 경우에 해당해야 하는 건데 NULL = NULL 조건은 FALSE기 때문~!
그리고 아래 두 쿼리처럼 사용하는 경우가 있는데..
-- 1번
WHERE 판매월 LIKE '2016%'
-- 2번
WHERE 판매월 BETWEEN '201601' AND '201612'LIKE는 성능상 비효율이 있을 수 있으나 BETWEEN은 성능적으로 범위검색에서 손해볼 것이 없다.
BETWEEN을 사용하면 LIKE와 달리 시작과 끝점이 🟰과 같아지기 때문.
🔶 선분이력의 인덱스 스캔 효율
선분이력이란 ? : 이력의 시작과 끝을 관리하는 것.
예) 사원의 입사일과 퇴사일을 한 레코드에서 관리할 경우를 말한다.
그러면 보통 사원번호, 입사일, 퇴사일 3가지의 컬럼을 가지고 인덱스를 구성할 텐데, 이때 가장 효율적인 인덱스 구성 방법은 무엇일까.
보통 아래와 같은 질의를 할 경우가 많다.
🔸어떤 사원이 특정 일에 근무를 했는가?
위는 아래 SQL로 표현 가능하다.
SELECT *
FROM 사원이력
WHERE 사원코드 = :CD -- '1234'
AND :DT BETWEEN 입사일자 AND 퇴사일자 -- '20240207'
;위 쿼리는 아래와 동일하다.
SELECT *
FROM 사원이력
WHERE 사원코드 = :CD -- '1234'
AND 입사일자 <= :DT -- '20240207'
AND 퇴사일자 >= :DT -- '20240207'
;여기서 고민.. 인덱스는 일단 사원코드가 🟰 조건이니 선두로 갈 것이고 입사, 퇴사일자는 둘다 범위 조건이니 둘 중에 어떤 질의를 하냐에 따라 체크조건으로 사용할 컬럼을 뒤로 빼는 선택을 해야한다.
✅ 수직적 탐색에 관여하는 Driving 조건으로 어떤 컬럼을 사용할 지 선택하는 것! (입사일자, 퇴사일자 중에)
따라서 최신 일자를 자주 조회한다면 (사원코드 + 퇴사일자 + 입사일자) 순으로 지정하는 것이 유리하다.
✅ 만약 (사원코드 + 입사일자 + 퇴사일자) 인덱스로 이미 지정 되어 있다면, 해당 인덱스를 index_desc 하고, 가장 마지막 데이터 1개만 가져올 것이니 rownum <= 1 조건으로 검색 효율을 높이자.
9. 인덱스 종류
🔷 B*Tree 인덱스
1) Unbalanced Index
- B*Tree 인덱스는 balanced 하므로 unbalanced 현상 안뜸~
2) Index Skew(비스듬한) 현상
- 한쪽이 비어버리는 현상
- 대량의 삭제 작업이 일어났을 때 발생함.
- 빈 블록은 Free List로 등록되지만 익스텐트를 반환하지는 않기 때문.
- 재사용은 가능하나, 다시 채워질 때 까지 인덱스 효율이 저하된다.
3) Index Sparse(부족한) 현상
- 대량의 삭제 작업후 발생함.
- 인덱스 밀도가 부족한 경우임.
- empty 블락은 아니나 밀도가 낮은 블록이 많은 경우.. 보통 총 레코드 건수가 일정한데 인덱스 공간이 지속적으로 증가하면 이 현상이라 한다.
4) 인덱스 재성성 하기 위한 확인 조건
- NL 조인에서 반복 액세스 되는 인덱스의 높이가 증가했을 때
- 대량의 delete 작업을 수행한 후 다시 레코드가 입력되기 까지 오랜 시간이 소요될 때
- 총 레코드 수가 일정한데도 index 크기가 증가할 때
🔷 비트맵 인덱스
1) 값의 Distinct Value 개수가 적을 때 사용(OLTP에선 그냥 쓰지마!)
2) 적은 용량을 차지함. 인덱스가 여러 개 필요한 대용량 테이블에서 유용함
3) 다양한 분석관점(Dimension)을 가진 팩트성 테이블에 주로 사용
4) 단독으로는 쓰이지 않음, 여러 비트맵 인덱스를 동시 활용 시 대용량 데이터 검색 성능 향상에 효과적임
🔸DML 부하가 큼(OLTP 쓰지말란 이유). 정형화 되지 않은 임의 질의 환경(ad-hoc query) 환경에 사용됨. (DW)
🔷 함수기반 인덱스
WHERE NVL(주문수량, 0) < 100;위와 같은 쿼리를 사용하는 경우에 인덱스를 아래와 같이 생성하면 컬럼이 가공되어도 인덱스를 탈 수 있다.
CREATE INDEX IDX_01 ON TABLE(NVL(주문수량, 0));다만, 데이터 입력, 수정 시 함수를 적용하여 인덱스에 반영해야 하므로 부하가 발생함.
🔸특히, User Defined 함수일 경우 그냥 쓰지 마세요.
🔷 리버스 인덱스
1) 입력되는 값이 순차적 증가로 리프 블록에만 데이터가 적재 될 때
🔸 Right Growing 현상 발생 시
2) insert가 심할 때 인덱스 블록 경합으로 초당 트랜잭션 처리량이 감소함
3) 입력된 값을 거꾸로 변환해서 저장함으로써 데이터를 고르게 분포시킨다.
4) 따라서 🟰 검색만 가능함. 범위 검색 조건은 사용 불가능.
10. 인덱스 설계
🔷 결합 인덱스 구성을 위한 기본 공식
🔹 조건절에 항상 사용되는가?
🔹 🟰 조건으로 사용되는가?
🔹 카디널리티가 좋은가?
🔹 소트 오퍼레이션을 생략 가능한 가?
🔷 추가적인 고려사항
🔹 인덱스 쿼리 수행 빈도가 높은 경우 (최적화 우선순위 1등임)
🔹 업무상의 중요도
🔹 클러스터링 팩터
🔹 데이터 량
🔹 DML 부하( = 기존 인덱스 개수, 초당 DML 발생량, 자주 갱신되는 컬럼 포함 여부 등)
🔹 저장공간
🔹 인덱스 관리 비용 등
⭕ 제 2절 조인의 원리와 활용
1. Nested Loop 조인
🔹 OLTP 환경이라면 보통 NL 조인을 사용한다.
✅ NL 조인은 반드시 인덱스가 있어야 하는데, 조인 쿼리에서 인덱스를 생성하는 방법은 아래와 같다.
SELECT *
FROM EMP E, DEPT D
WHERE E.JOB = 'WORK'
AND E.DEPT_NO = D.DEPT_NO
AND D.DEPT_NM = 'TEACHER'위와 같은 쿼리가 있다면 먼저 어떤 테이블이 드라이빙이 되야 할 지 확인해야 한다.
드라이빙 될 테이블은 무조건! 작아야 유리하다.
따라서 보통 DEPT가 드라이빙 테이블로 선정될 테니 인덱스를 생성하자면,
1. DEPT가 드라이빙 테이블일 경우
D (DEPT_NM)
E (DEPT_NO + JOB)위와 같이 구성하는 것이 효율적이다.
D 테이블의 경우 조건절로 사용되는 컬럼은 DEPT_NM 하나 뿐이므로 해당 조건으로 인덱스를 생성하고,
D 테이블에 대한 결과로 E 테이블의 질의되므로, 위 쿼리에서 E 테이블이 INNER 테이블의 역할을 할 때는 아래와 동일한 쿼리가 된다.
SELECT *
FROM EMP E
WHERE E.JOB = 'WORK'
AND E.DEPT_NO = :DEPT_NO -- DEPT 테이블에서 가져온 결과 데이터✅ 그럼 DEPT_NO와 JOB은 둘다 🟰 조건이니 인덱스를 뭐가 앞에 놓던 효율은 같을텐데 어떤 기준으로 DEPT_NO를 선두에 놓았냐?
.. 조인 조건으로 사용되는 컬럼은 타 쿼리에서도 사용될 확률이 높으니 보통! 선두로 놓는게 이득이라 그렇다..
2. EMP가 드라이빙 테이블일 경우
E (JOB)
D (DEPT_NO + DEPT_NM)이렇게 구성하면 되겠다.
🔶 NL 조인 특징
🔸 Random Access 위주의 조인
🔸 조인을 한 레코드씩 순차적으로 진행한다.
🔸대용량 처리 시 치명적인 한계점 발생
🔸인덱스 구성 전략이 중요함
🔸OLTP 환경에 적합
🔷 테이블 Prefetch
🔹 Disk I/O 부하를 감소시키기 위한 기능
🔹 multiblock I/O도 Prefetch 기능 중 하나임
🔹 한번에 여러 개 Single Block I/O를 동시에 수애한는 것
✅ Multiblock I/O : 하나의 익스텐트 내의 인접한 블록을 동시에 읽는 것
✅ Prefetch : 서로 다른 익스텐트에 위치한(인접하지 않은) 블록을 배치 방식으로 미리 적재하는 것.
🔷 Batch I/O
🔹 Disk I/O 필요 시 즉시 I/O 하지 않고 임시 저장 후 적당량 쌓이면 한 번에 Disk I/O 한 후 조인 수행
🔹 한번에 Disk I/O 하므로 정렬 순서가 인덱스 순서와 달라질 수 있음.
✅ 이런 이유 때문에 Index 힌트만 사용하고 Order by 절을 생략한 경우 정렬 순서가 다를 수 있음.
2. Sort Merge 조인
🔶 Sort Merge 조인 특징
🔸 소트 단계 : 양쪽 집합을 조인 컬럼 기준으로 정렬 ➡️ PGA에서 정렬한다
🔸 머지 단계 : 정렬된 양쪽 집합을 Merge
🔸 조인을 위해 실시간으로 인덱스를 생성하는 것과 같은 효과이다. (부화 오지겠는걸)
🔸양쪽 집합을 정렬 후 NL 조인과 동일한 방식으로 진행
🔸 PGA 영역에서 처리하므로 굉장히 빠른 속도임(소트 부하만 감수한다면.. 버퍼 캐시에서 조인하는 NL보다 빠름)
🔸 조인 컬럼에 인덱스 없어도 됨
🔸 부분적으로 부분범위 처리가 가능하다.
3. Hash Join

🔹 조인 연결고리로 Hash Function을 사용
🔹 두 개의 테이블 중 작은 집합을 읽어 Hash Area에 적재함.(= Build input)
➡️ Hash Area에 올라갈 정도로 작아야 한다
🔹 반대쪽 큰 집합을 읽어 해시 테이블을 탐색한다( = Probe Input)
🔹 🟰 조건만 사용 가능
➡️ Hash Function을 사용하니 equal 조건만 가능한 것은 당연하지.

🔹 가장 작은 테이블을 Build Input으로 지정해야 하므로 D를 지정할 것임.
🔹 위 쿼리에선 NO_SWAP_JOIN_INPUTS 힌트로 X 테이블을 Build Input에서 제외시켰음 = Probe Input으로 사용
🔹 ORDERED 힌트로 인해 D E X 순으로 조인되므로 D는 자동으로 Build Input이 됨.
⭕ Probe Input이 조인으로 구성될 경우
Probe Input이 완료되어야 Build Input과 조인이 가능함. 따라서 Probe Input이 조인으로 구성될 경우 먼저 선행됨!
5. 조인순서의 중요성
🔷 Sort Merge 조인의 순서
🔹 Disk Sort가 필요할 경우 : 큰 테이블이 Driving이 유리 (Disk I/O 횟수를 감소시킴)
🔹 PGA Sort Area에 담길 경우 : 작은 테이블이 Driving 이 유리함.(Join 횟수 감소)
🔶 Hash 조인의 순서
🔸 NL이랑 똑같이 그냥 무조건 작은 게 Driving!!!!!! = Build Input
⭕ NL 조인과 Sort Merge 조인을 Outer 조인할 때 Outer 테이블이 아닌 테이블을 Driving으로 지정 할 수 없다
⭕ 다만 Hash Join은 오히려 Outer 테이블이 아닌 테이블을 Driving 조인해야 수월하다

6. 스칼라 서브쿼리를 이용한 조인
🔹 Scalar Sub-Query : 하나의 값만을 반환하는 쿼리
🔹 수행회수 최소화를 위한 캐싱 기능
➡️ 10g 이후는 _query_execution_cache_max_size 만큼(11g의 경우 65,536개)
➡️ 입력되는 값( 메인쿼리의 결과값 )이 캐시 수보다 작아야 한다.
➡️ 코드성과 같이 동일 값이 자주 나타나야 효과적임
참고 강의 관련 카페 주소(오프라인 교육) :
https://cafe.naver.com/dbstudydapsqlp
데이터와사람들 : 네이버 카페
데이터베이스 교육 및 스터디를 위한 커뮤니티입니다.
cafe.naver.com
다음 내용 :
2024.02.19 - [자격증/SQLP] - [SQLP 요약] 제 5, 6장 (이력, 소계, Top N, 고급 SQL 튜닝) - (3/4)
[SQLP 요약] 제 5, 6장 (이력, 소계, Top N, 고급 SQL 튜닝) - (3/5)
이전 내용 : 2024.02.07 - [자격증/SQLP] - [SQLP 요약] 제 5장 인덱스와 조인 (2절 조인의 원리와 활용) - (2/5) [SQLP 요약] 제 5장 인덱스와 조인 (2절 조인의 원리와 활용) - (2/5) 이전 내용 : 2024.01.29 - [자격
holog.tistory.com
'자격증 > SQLP - 완 -' 카테고리의 다른 글
| [SQLP] 시험 직전에 볼 내용들 모으기 (0) | 2024.02.23 |
|---|---|
| [SQLP 요약] 제 5, 6장 (이력, 소계, Top N, 고급 SQL 튜닝) - (3/4) (0) | 2024.02.19 |
| [Oracle] Plan 보는 법(DBMS_XPLAN.DISPLAY_CURSOR) (0) | 2024.02.02 |
| [SQLP 요약] 제 5장 인덱스와 조인 (1절 인덱스 구조 및 종류 이해) - (1/4) (6) | 2024.01.29 |
| [SQLP] 정규식 REGEXP_SUBSTR (0) | 2024.01.09 |