SQLP 시험 영역 중 "과목 3. SQL 고급 활용 및 튜닝"에 대한 강의(개인적으로 수강 중인 교육)를 요약해서 업로드하려 한다. (사실 강의에서 매주 숙제가 그 주 수업 요약이다)
나도 나중에 시험 전에 참고 하려 블로그에 올린다.
🏳️🌈 이번 주 목차
제 5장. 인덱스와 조인
└ 1절. 인덱스 구조 및 종류의 이해
├ 1. 인덱스 구조
├ 2. 인덱스 기본원리
├ 3. 다양한 인덱스 스캔방식
├ 4. Oracle DBMS 구조
├ 5. 테이블 랜덤 액세스 부하
├ 6. 테이블 Random 액세스 최소화 튜닝
├ 7. IOT와 클러스터
├ 8. 인덱스 스캔 효율
├ 9. 인덱스 종류
└ 10. 인덱스 설계
└ 2절. 조인의 원리와 활용
├ 1. Nested Loop 조인
├ 2. Sort-merge 조인
├ 3. Hash 조인
└ 4. 조인 순서의 중요성
1. 인덱스 구조
인덱스는 기본적으로 Key + RowID로 구성되어 있으며 정렬되어 있는 구조이다.

좌측 표처럼 특정 값을 가지고 정렬되어 있는 Index Key와 비교하여 값을 찾은 후에
RowID를 이용하여 Table에 Random Access하여 결과를 출력한다.(보통)

인덱스와 테이블을 비교하였을 때 Leaf Node 수는 동일 하지만,
인덱스는 Key와 RowID만을 저장하기에 평균 Row 용량 및 테이블 용량, 그리고 블록 수에서 확연한 차이가 발생한다.
(또한 테이블은 Free Block에 빈 공간이 있으면 아무렇게나 저장한다.)
1번째 쿼리는 인덱스를 이용한다면 인덱스 시작지점부터 수직적 탐색 후에 사번이 10보다 커질 때 까지 수평적 탐색하여 10개의 RowID만 추출한다.
2번째 쿼리도 인덱스를 반대로 스캔하여 1번과 마찬가지로 10개의 RowID만 추출한다.
3번째 쿼리 또한 1번의 수직적 탐색을 진행한 후 (사번이 5억인 것 부터) 5억+10보다 커질때까지 10개의 RowID만 추출한다.
반면, 인덱스가 없다면 Table Full Scan을 하면서 3개의 쿼리 모두 10억개의 Row를 읽게 된다.

인덱스는 Root 노드, Branch 노드, Leaf 노드로 구성된다.

크기가 작은 인덱스의 경우 Root와 Leaf 노드가 한개로 구성되고 branch가 생략된 형태가 있을 수 있다.

당연히 branch의 level(Depth)가 늘어날 수록 인덱스에 저장 가능한 Leaf수가 곱절로 증가한다.

1. 인덱스는 정렬된 형태이기 때문에 root 블록부터 branch 블록을 이동하면서 Range Scan의 시작이 될 '강성욱'을 찾는다
2. '강성욱' 부터 '최지성'이 나올때까지 수평적 스캔을 진행한다.
위 작업은 아래 그림으로 표현한다.

1. 수직적 탐색 : Root > Branch > Leaf 순으로 찾아가는 탐색
2. 수평적 스캔 : 수직적 탐색으로 찾은 Leaf에서부터 종료점 까지 범위 스캔 하는 것(Sequential Access)
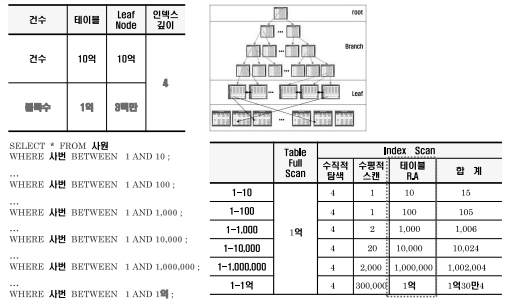
수평적 스캔에 따른 R.A 발생 건수가 오히려 인덱스를 사용하지 않고 Full Scan할 때 보다 총 읽는 블록수가 증가할 수 있는 것을 알 수 있다. (또한 Multi i/o를 배제한 결과이다)
따라서 인덱스를 사용하여 결과를 호출할 때 총 테이블 건수 대비 인덱스 사용 효율에 대한 손익분기점은 대략 10~15% 이하이다. (인덱스 사용 시 발생하는 테이블 R.A가 굉장히 부담되는 작업이기 때문)
| Sequential Access | Random Access |
| 하나의 블록에서 순차적으로 읽음 Index Leaf Block 읽을 때 / Full Scan 할 때 발생 비용이 적음 Full Scan 일 경우 Multi - Block I/O 가능 |
주로 하나의 블록에서 하나의 레코드만 읽는다 효율이 낮다 / 비용이 많이 든다 Rowid를 이용한 테이블 액세스다 DBA(Data block Address)를 이용한 인덱스 수직적 탐색 (다음 로우 읽으려 해도 무조건 Root부터 읽어야 한다) 클러스터링 팩터가 낮을 때 비교적 높은 성능을 보인다(뒤에서 설명) Single block I/O |
비용 효율은
테이블 R.A >> 수직적 탐색 >> 수평적 스캔 순으로 좋다.
2. 인덱스의 기본 원리
인덱스는 아래의 경우 사용이 불가능하거나 범위 스캔이 불가능하다.
1. 인덱스 컬럼을 가공한 경우
2. Null 을 검색하려 한 경우
3. 묵시적 형변환이 일어난 경우
4. 부정검색을 한 경우

인덱스 사용 관련 참고사항)
Null 데이터는 인덱스를 만들지 않는다.
문자 = 숫자 비교 시 문자가 숫자로 묵시적 형변환 됨.
변환 불가능 할 경우 ERROR 발생함.
단, Like 검색의 경우 숫자 > 문자로 묵시적 형변환 됨.
문자 = 날짜의 경우 문자를 날짜로 형변환됨.
3. 다양한 인덱스 스캔 방식
인덱스 스캔 방식
| Index Range Scan | In-List Iterator |
| Index Full Scan | Index Fast Full Scan |
| Index Unique Scan | Index Range Scan Descending |
| Index Skip Scan | Index Combine |
1. Index Range Scan
항상 빠른 속도를 보장하진 않음.(손익 분기점 10~15% 이하)
SQL 튜닝의 핵심 원리 두가지
1. 인덱스 스캔하는 범위를 얼마나 줄일 수 있는가?
2. 테이블로 액세스 하는 회수를 얼마나 줄일 수 있는가?
인덱스를 구성하는 선두 컬럼을 조건절에 반드시 사용해야 한다.
Range Scan을 유도하는 힌트는 없으며, 그냥 Index 힌트를 사용한다.
인덱스가 (이름 + 부서코드) 이고 조건절에 이름에 대한 조건만 존재한다면 Index Range Scan이 발생할 것임.

2. Index Full Scan
적당한 인덱스가 없을 경우 사용되기도 함
조회 조건의 인덱스가 있으나, 선두 컬럼이 아니지만 옵티마이저가 이득이다 판단 할 시 발생함
별도의 힌트는 없음
- 최종 결과 값이 적을 때 Full Table Scan 보다 Index Full Scan이 효율적이다.
3. Index Unique Scan
수직적 스캔만 발생한다.
Unique 인덱스 일 경우 사용된다.
= 조건일 때만 사용된다
4. Index Skip Scan
인덱스를 구성하는 선두 컬럼의 분포가 낮으면서(distinct가 적을 때) 선두 컬럼 이후의 컬럼만 조건에 사용 될 시 발생.
힌트 : /*+ index_ss( e index_name) */

인덱스 선두 컬럼이 Between, like, 부등호 일때도 사용된다.
5. Index Fast Full Scan

전체 Index를 Full Scan 한다.
Multi-Block I/O
파라미터의 db_file_multiblock_read_count 개수만큼 한번에 Read 된다
-> 보통 해당 파라미터를 128을 지정한다. 왜냐하면 128 * 8k(블록 크기) = 1MB인데, 이게 보통 OS의 운반 단위이기 때문에 최대한 최적화 하려는 용도이다.
다만, 해당 크기는 1 Extent의 크기를 넘지 못한다. 그래서 내가 멀티블록I/O의 크기는 1 Extent 크기라고만 잘못 알고 있었다.
Index의 물리적 순서와 무관하게 물리적 순서대로 읽으니 결과값의 순서가 보장되지 않는다.
힌트 : index_ffs

6. Index Range Scan Descending
반대로 읽기임. 끝.
힌트 : Index_desc
4. Oracle DBMS 구조

오라클 DB는 크게 두가지로 나뉜다.
1. Database 2. Instance
Database는 3가지로 나뉜다.
1. Datafiles
- 흔히 생각하는 데이터 저장되는 Files
2. Control files
- DB Open 시점에 있어야 할 Files
3. Redo Log Files
- 한개의 Redo Log Files가 다 사용되면 Archived Log Files로 저장됨.
- 그리고 다음 Redo Log Files에 쓰이게 됨.
- DB Recovery 시에도 사용 됨
Instance는 크게 두가지로 나뉜다.
1. Back Ground Process 2. SGA
Back Ground Process는 5가지로 나뉜다.
1. PMON
- User로부터 할당된 프로세스가 죽을 시에 좀비프로세스로 변하는데 이 영역을 모니터링하다가 해당 좀비 프로세스를 Kill 해주고 PGA 영역을 반환해줌
- Server Process는 옵티마이저의 모듈을 가져다가 호출하면서 실행계획을 만듬. 실제로는 얘가 실행계획을 만드는 행위를 한다고 볼 수 있음.
2. SMON
- instance Recovery를 해줌. (= memory Recovery)
- DB가 죽었다가 살아날 때 하는 Recovery임
- (1) 마지막 CKPT 이후부터 Roll Forword 진행. (Redo Log File을 읽어서 진행함)
- (2) Roll Back(Undo 읽음)
- (3) CKPT를 발행함
3. DBWR 4. LGWR
5. CKPT
- Memory와 DB File의 동기화를 보장해줌.
- 나중에 Recovery 등의 작업 때는 해당 CKPT가 찍힌 시점 부터만 Roll Forword 하면 됨.
SGA는 아래로 나뉜다.
1. Shared Area(Dictionary Cache, Library Cache) 2. Data Buffer Cache
3. Redo Log Buffer
- Insert, Delete, Update 시에 쌓임
- DB 복구 시 위의 SQL을 재 실행 하기 위한 정보임
- DML로 수정된 Before, After 이미지
- DML 발생 시 DB Buffer Cache보다 먼저 저장됨 (WAL!!)
- User Commit 등의 상황에 Redo Log File 저장
- DB Buffer Cache에는 레코드 수가 아닌 블록 단위로 Write 됨.
- 반면에 로그 버퍼는 append 방식으로 Write 되니 훨~씬 빠르고 적은 부하임.

5. 테이블 Random Access 부하
인덱스로 데이터 읽는 순서
1. Index에서 Key에 해당하는 RowID 값을 가지고 메모리를 찾는다.
2. 이때 메모리에 로우 하나를 읽는 게 아닌 그 블록을 찾아 감.
3. 없으면 disk I/O 함
RowID는 오파블로 구조임
1. 데이터 오브젝트 번호 (6자리)
2. 데이터 파일 번호 (3자리)
3. 블록번호 (6자리)
4. 로우번호 (3자리)
1~3번은 DBA(Data Block Address) 라고함. DBA + Row Address = RowID임.
* R.A는 왜 부하가 심한가?

RowId를 취득한 후엔 DBA를 Hash Func에 넣어서 Hash_Bucket을 취득한다.
(Hash 알고리즘은 나머지 함수 알고리즘과 동일하다.)
이때 취득한 Hash_Bucket으로 찾아가기 위해 Cache Buffer Chain Latch 경합을 시도하는데, Latch 방식이란
먼저 잡는 놈이 장땡 방식이다. Queue가 아님. 2000번까지 시도하다 안잡히면 그때 다양한 Wait Event가 발생하는 것임.
일단 여기서 1차 싸움을 해야함.
그 다음 경합에 이겨도 Buffer Block(메모리) 에서 Buffer Block 대기 이벤트가 발생할 수가 있음.
또.. LRU 알고리즘에 의해 메모리에서 해당 블록이 Age Out 되었을 경우 LRU Latch를 획득 해야한다.

방금 말한 Age Out을 방지하기 위한 기법이 Buffer Pinning 이다.
요놈은 인덱스에서 RowId를 취득할 때 바로 다음 RowID를 체크한 후 지금 읽을 블록과 동일한 블록을 읽는다면 그 블록을 읽으면서 Age Out 되지 않도록 Pin을 걸어두는 것임.
Pin을 걸어두는 것과 동시에 해당 DBA가 가리키는 메모리 주소를 PGA에 저장해서 바로 찾아가게됨.
이 내용만 보면 C.F가 왜 성능에 영향이 큰 지 알수 있음.(바로 다음 블록 DBA가 현재와 같다가 Buffer Pinning에 발생 조건이니까)
Buffer Pinning은 LR(Logical Read) Count로 잡히지 않음. 뒤에 실행계획에서 알 수 있음.
(LR(Logical Read) : 메모리에서 읽은 것, PR(Physical Read) : Disk 에서 읽은 것.. LR은 PR을 포함한다. PR도 결국 메모리에 올려서 읽으니까)
+ NL 조인할 때 드라이븐 테이블(뒤에 조인되는 테이블)의 Root 리프도 Buffer Pinning 대상이 된다.
* Clustering Factor

인덱스를 순차적으로 읽었을 때 이전 Rowid 블록과 다음 Rowid 블록이 다르면 증가시키면서 체크하면 됨. 작을 수록 좋은거지. 방금 말했던 것처럼 Buffer Pinning으로 인해 LR도 발생 안되고 R.A 효율이 급상승 하게 된다.
요 C.F 때문에 무조건 인덱스 효율의 손익분기점이 10%가 되지많은 않음. 정확히는 C.F에 의해 좌우된다!
요 C.F를 극복하기 위한 방법이
SQL Server : Clustered Index
Oracle : IOT
되시겠다.
왜냐.. I/O 튜닝의 핵심 원리 두가지가 이거니까.
1. Sequential 액세스의 선택도를 높인다.
2. Random 액세스 발생량을 줄인다.
6. 테이블 Random 액세스 최소화 튜닝
아래 사진과 같은 인덱스 구성과 쿼리일 때 "근무지" 컬럼을 인덱스 컬럼에 추가하려면 어떻게 해야 할 까

기존 인덱스를 그대로 사용한다면 인덱스를 타더라도 성별이 '남'인 모든 사원을 R.A 할 수 밖에 없다.
인덱스를 [성별 + 근무지]로 구성한다면 가장 좋겠지만, 테이블 1개에 인덱스는 최대 3~5개 이하로 하라고 하셨고.. 최대한 개수를 줄이라고 하셨다.
그럼 [성별 + 연봉 + 근무지] 로 한다면 효율이 어떨까.
그럼 성별은 '남'인 사원 중에 모든 연봉을 다 훑고.. 그 중 근무지가 '광주' 인 것들을 집어서 R.A 하게 될 것이다.
상당히 비효율 적으로 보일 수 있으나, 차라리 성능 저하에 적은 영향을 끼치는 수평적 탐색에서 Filtering을 하는 것이 좋다는 것을 말하고 싶은 듯 하다.
+ SQLP 튜닝에서는 Index Only Scan을 유발시키기 위해 인덱스에 select 컬럼을 추가하는 짓은 감점이라고 한다. 참고하자
7. IOT와 클러스터

아까 봤던 Buffer Pinning의 효과를 극대화 하는 경우이다.
왼쪽은 L.R이 5번 일어났는데, 우측은 2번으로 끝났다. C.F의 중요성을 보여주려는 비교사진이다.
* Oracle의 IOT(Index Orgarnized Table)
Oracle의 IOT는 인덱스 Leaf Node가 [Key + Data] 로 구성된다.

IOT는 PK까지만 사용했을 때는 굉~장히 빠르다. Leaf 블록이 Key와 Data로 구성되어 있으니 R.A가 없기 때문.
다만, 2번째 key부터 문제가 발생하는데 Secondary key가 [key + PK]로 구성된다는 것이다.
이게 무슨말이냐면, IOT는 특성상 정렬형태를 유지해야 하므로 데이터의 Insert Update Delete가 일어날 때 마다 블록 Split이 일어날 수가 있다. 이 때문에 다른 테이블의 인덱스처럼 RowId를 고정할 수가 없는데, 그래서 RowId가 아닌 논리적인 PK값을 저장하기 때문에 수직적 탐색을 한번 더 해야만 실제 데이터를 찾아갈 수 있기 때문이다.
| SQL Server ( Clustered Index ) | Oracle (IOT ) |
| PK가 아니더라도 일반 Key로 생성 가능 | PK로만 생성 가능 |
* Oracle IOT를 활용하는 경우
크기가 작고 NL 조인으로 반복 드라이븐 되는 테이블
폭이 좁고 긴(row 수가 많은) 테이블 = 교차 엔터티
넓은 범위를 주고 검색하는 테이블
데이터 입력과 조회 패턴이 서로 다른 테이블
* Oracle의 Cluster Index
클러스터 인덱스에 특정 값을 지정해 놓고, 해당 값이 같은 레코드가 물리적으로 한 블록에 모이도록 저장하는 구조.
한 블록이 넘으면 새로운 블록을 할당하고 클러스터 체인으로 연결한다.
넓은 범위 검색에 유리하며,(C.F가 매우 좋음)
새로운 값이 자주 입력되거나(클러스터 할당해야함) 수정이 자주 발생하면(클러스터 자주 이동됨) 좋지 않다.
8. 인덱스 스캔 효율
1. 인덱스 매칭도
equal(=) 또는 IN 조건이 아닌 조건 이후에는 체크 조건이 된다.
인덱스 컬럼이 [A + B + C] 일 때
where A = 1 and B > 3 and C = 3
같은 조건이라면, A, B는 드라이빙 조건이지만 C는 체크조건이 될 수 밖에 없음.
(체크조건 : 조건을 모두 만족하지 못하고 Filtering 해야하는 등의 수평적 스캔 비효율이 발생 하는 조건)
* 결합 인덱스 우선순위 결정
- 항상(자주) 사용되는 가?
- "=" 조건으로 사용되는 가?
- Cardinality(분포도)가 좋은가?
- 소트 연산 대체가 가능한가?(부분범위처리, 게시판 쿼리 등)
* 실행계획으로 효율성 보기

나중에 나오겠지만.. 위 그림에서 보면
Starts : 실행 회수 ( 수직적 탐색 수)
E-Rows : Estimate Rows, 예상 로우 수
A-Rows : Active Rows, 실제 로우 수
* 점선 네모친 부분 보면 index range scan으로는 7건 읽었는데 R.A하면서 3건으로 줄었다. 4건을 테이블에서 filter 했으니 R.A 손해가 발생했다는 걸 알 수 있다!
A-Times : 실행 시간
Buffers : L.R 블록 수. 하위 레벨 계획의 블록 수를 포함한다.
Reads : P.R 블록 수
아래에 Predicate information에서도 보면 3에서 filter 조건이 발생했다. 요게 뭐냐면..
| Predicate에 나온 것 -> | Access | Filter |
| Index | Drive 조건 | Check 조건 |
| Table | 안나옴. | Random Access 비효율임 |
요 표로 나타낼 수 있는데 Table에서 Filter 이므로 R.A 비효율이 나타난 것 이라는 뜻이다.
이번주는 여기까지.
참고 강의 관련 카페 주소(오프라인 교육) :
https://cafe.naver.com/dbstudydapsqlp
데이터와사람들 : 네이버 카페
데이터베이스 교육 및 스터디를 위한 커뮤니티입니다.
cafe.naver.com
다음글 :
2024.02.07 - [자격증/SQLP] - [SQLP 요약] 제 5장 인덱스와 조인 (2절 조인의 원리와 활용) - (2/4)
[SQLP 요약] 제 5장 인덱스와 조인 (2절 조인의 원리와 활용) - (2/5)
이전 내용 : 2024.01.29 - [자격증/SQLP] - [SQLP 요약] 제 5장 인덱스와 조인 (1절 인덱스 구조 및 종류 이해) - (1/5) [SQLP 요약] 제 5장 인덱스와 조인 (1절 인덱스 구조 및 종류 이해) - (1/5) 더보기 SQLP 시험
holog.tistory.com
'자격증 > SQLP - 완 -' 카테고리의 다른 글
| [SQLP 요약] 제 5, 6장 (이력, 소계, Top N, 고급 SQL 튜닝) - (3/4) (0) | 2024.02.19 |
|---|---|
| [SQLP 요약] 제 5장 인덱스와 조인 (2절 조인의 원리와 활용) - (2/4) (2) | 2024.02.07 |
| [Oracle] Plan 보는 법(DBMS_XPLAN.DISPLAY_CURSOR) (0) | 2024.02.02 |
| [SQLP] 정규식 REGEXP_SUBSTR (0) | 2024.01.09 |
| [SQLP] 시험 준비 (0) | 2023.12.29 |